Παραγωγική Τεχνητή Νοημοσύνη (Generative AI)
Καλωσορίσατε στο δεύτερο μάθημα Τεχνητής Νοημοσύνης και Μηχανικής Μάθησης (Machine Learning). Την πρώτη σειρά μπορείτε να τη βρείτε εδώ. Σε αυτή τη δεύτερη σειρά διαλέξεων, στρέφουμε την προσοχή μας στις ιδέες, στις τεχνικές και στις εφαρμογές που συνολικά συντελούν αυτό που αποκαλείται Παραγωγική Τεχνητή Νοημοσύνη (Generative AI).
Θα αρχίσουμε εκεί όπου κατέληξε η πρώτη σειρά διαλέξεων και θα προχωρίσουμε στην ανάπτυξη τόσο των βασικών ιδεών όσο και της υλοποίησής τους στην Python και PyTorch, χτίζοντας, εκπαιδεύοντας και χρησιμοποιώντας βαθιά νευρωνικά δίκτυα και μεγάλα γλωσσικά μοντέλα (LLMs) που παράγουν εικόνες και φυσική γλώσσα (κείμενο). Εν συντομία, σκοπός μας είναι να αναπτύξουμε μια “λειτουργική” κατανόηση των βασικών ιδεών πίσω από την παραγωγική τεχνητή νοημοσύνη, και τα συστήματα που τη χρησιμοποιούν. Συστήματα όπως τα μοντέλα της OpenAI (GPT, DALL·E, κ.α.), της Anthropic (Claude), της Google (Gemini, κ.α.) αλλάζουν ριζικά πολλές πτυχές της καθημερινής μας ζωής.
Οι διαλέξεις έχουν ως αφετηρία τη βασική ερώτηση «Τι είναι η παραγωγική τεχνητή νοημοσύνη;» Κατά πρώτη όψη, ο στόχος της παραγωγικής τεχνητής νοημοσύνης είναι, όπως το λέει και το όνομα, η παραγωγή – παραγωγή κειμένου, εικόνων, κώδικα, βίντεο, ή ενδεχομένως οτιδήποτε άλλο μας ενδιαφέρει. Η χρησιμότητά της, όμως, εκτείνεται σε πολύ ευρύτερο φάσμα εφαρμογών. Όπως θα δούμε, η πραγματική ουσία της παραγωγικής τεχνητής νοημοσύνης είναι ο τρόπος με τον οποίο αναπτύσσει μια (τεχνητή) αντίληψη του «σύμπαντος» στο οποίο αναφέρεται (εικόνων, κειμένων, κ.ο.κ.). Η ιδέα αυτή – η ανάπτυξη τεχνητής αντίληψης – είναι πιο αφηρημένη από τους συγκεκριμένους στόχους που σηματοδότησαν την πορεία μας στο πρώτο μάθημα, όπου χτίζαμε εργαλεία για να πετύχουμε καλή ακρίβεια σε προβλήματα παλινδρόμησης και ταξινόμησης. Ωστόσο, θα βρούμε την αρχή του νήματος στις τελευταίες διαλέξεις της πρώτης σειράς, όπου αναπτύξαμε την ιδέα του Transfer Learning.
Από το Transfer Learning, μπαίνουμε κατευθείαν στην ουσία: Σημασιολογικές Ενσωματώσεις (semantic embeddings). Οι ενσωματώσεις είναι η γέφυρα που συνδέει τις ιδέες της τεχνητής νοημοσύνης που συζητήσαμε στο πρώτο μάθημα με την παραγωγική τεχνητή νοημοσύνη. Στην πορεία μας θα συναντήσουμε διάφορες εφαρμογές. Μία από τις σημαντικότερες είναι η αναζήτηση σε βάση γνώσης, που θα μας οδηγήσει στα συστήματα RAG (Retrieval-Augmented Generation), που επιτρέπουν στα μεγάλα γλωσσικά μοντέλα να αξιοποιούν εξειδικευμένα κείμενα πάνω στα οποία δεν έχουν εκπαιδευτεί.
Οι διαλέξεις αυτής της σειράς είναι πιο απαιτητικές από αυτές της πρώτης σειράς. Παίρνουμε ως δεδομένες τη γνώση και την εξοικείωση με την υλοποίηση και την εκπαίδευση βαθιών νευρωνικών δικτύων. Αναγκαστικά, θα χρειαστούμε και κάποιες σημαντικές ιδέες και έννοιες από τα μαθηματικά, όπως τη γεωμετρία του εσωτερικού γινομένου. Όπως και με την πρώτη σειρά, ο στόχος μας εδώ είναι να εισάγουμε έναν πυρήνα επιλεγμένων βασικών ιδεών που μπορεί να επεκταθεί εύκολα, αλλά και να χρησιμοποιηθεί άμεσα. Ωστόσο, την ανάπτυξη μαθηματικών ιδεών που ενδεχομένως εμπλουτίζουν/εμβαθύνουν την κατανόηση, αλλά δεν είναι αυστηρά απαραίτητα, την αφήνουμε για μια συμπληρωματική σειρά διαλέξεων πάνω στο μαθηματικό υπόβαθρο της τεχνητής νοημοσύνης.
Οι διαλέξεις αντλούν από τη διδασκαλία μου στο Πανεπιστήμιο του Τέξας στο Ώστιν (UT Austin) και έχουν σχεδιαστεί για μαθητές του λυκείου (και για οποιονδήποτε άλλο διαθέτει το κατάλληλο υπόβαθρο) που έχουν παρακολουθήσει την πρώτη σειρά διαλέξεων και είναι έτοιμοι για το επόμενο βήμα.
Θα βρείτε παρακάτω συνδέσμους προς τις διαλέξεις, οι οποίες είναι οργανωμένες θεματικά σε «ενότητες». Η δομή των διαλέξεων είναι παρόμοια με αυτήν της πρώτης σειράς: χρησιμοποιούμε διαφάνειες όταν πρωτοεισάγουμε και εξηγούμε μια καινούργια ιδέα, και στις επόμενες διαλέξεις αναπτύσσουμε και υλοποιούμε αυτές τις ιδέες στην Python, επιλύοντας χαρακτηριστικά προβλήματα που βασίζονται κατά περίπτωση σε πραγματικά ή αληθοφανή τεχνητά δεδομένα.
Python και Colab: θα χρησιμοποιήσουμε τη γλώσσα προγραμματισμού Python. Ο προγραμματισμός γίνεται στο Colab. Το Colab είναι ένα δωρεάν, βασισμένο στο cloud εργαλείο από την Google, το οποίο επιτρέπει τη συγγραφή και την εκτέλεση κώδικα Python σε περιβάλλον Jupyter Notebook. Δουλεύει εξ ολοκλήρου στον browser, χωρίς να απαιτείται εγκατάσταση λογισμικού ή ρύθμιση περιβάλλοντος, οπότε η χρήση του εξασφαλίζει σε όλους πρόσβαση στο ίδιο υπολογιστικό περιβάλλον. Θα χρειαστείτε όμως λογαριασμό Gmail.
Πώς μπορείτε να χρησιμοποιήσετε την ύλη του μαθήματος:
2. Όποιος ενδιαφέρεται για μια γρήγορη επισκόπηση του μαθήματος, μπορεί να παρακολουθήσει μόνο τις διαλέξεις με διαφάνειες. Οι λοιπές διαλέξεις όπου υλοποιούμε αλγορίθμους σε Python έχουν στον τίτλο την επισήμανση "(Python / Colab)".
3. Εάν έχετε ήδη εμπειρία χρησιμοποιώντας την Python και έχετε κάποια επαφή με τις ιδέες και τους αλγορίθμους της παραγωγικής τεχνητής νοημοσύνης που συζητάμε, μπορείτε απλά να πάτε κατευθείαν στα Colab Notebooks που σας ενδιαφέρουν.
4. Τα μαθήματα/διαλέξεις που συμπεριλαμβάνονται στην ιστοσελίδα αποτελούν έναν αρχικό αλλά εξελισσόμενο βασικό κορμό ή πυρήνα. Πρόσθετες διαλέξεις θα είναι διαθέσιμες στην ιστοσελίδα στο άμεσο μέλλον.
Εδώ θα βρείτε σύνδεσμους (links) για την πλήρη ύλη του μαθήματος:
Ενότητα 1: Εισαγωγή στο Μάθημα και στην Παραγωγική Τεχνητή Νοημοσύνη
-
Διάλεξη 1: Τι είναι η Παραγωγική Τεχνητή Νοημοσύνη; Τι θα καλύψει αυτό το μάθημα;

Σε αυτή τη διάλεξη δίνουμε κάποια πρώτα παραδείγματα, και ύστερα περιγράφουμε συνοπτικά όλο το μάθημα, τη δομή των διαλέξεων, τη σχέση με την πρώτη σειρά διαλέξεων για τη Μηχανική Μάθηση και την Τεχνητή Νοημοσύνη, και τις προαπαιτούμενες γνώσεις για να παρακολουθήσετε τα μαθήματα.
-
Διάλεξη 2: Από την Τεχνητή Νοημοσύνη στην Παραγωγική Τεχνητή Νοημοσύνη
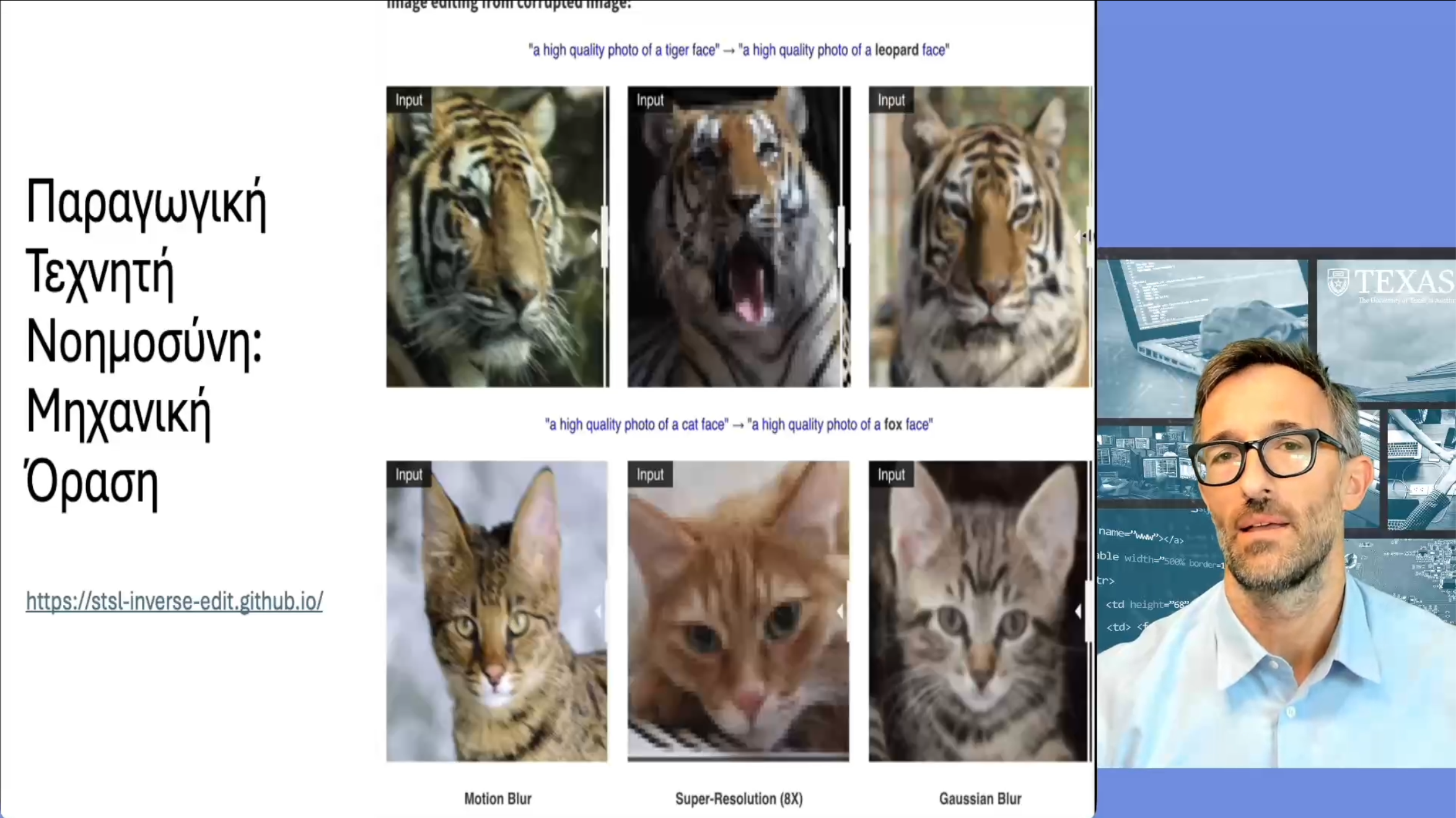
Σε αυτή τη διάλεξη συνεχίζουμε την εισαγωγική μας συζήτηση για την παραγωγική τεχνητή νοημοσύνη και τις εφαρμογές της. Η διάλεξη συνοψίζει, χρησιμοποιώντας συγκεκριμένα παραδείγματα από τη μηχανική όραση, τη σχέση αλλά και τις ουσιαστικές διαφορές της παραγωγικής τεχνητής νοημοσύνης από όλα όσα καλύψαμε στην πρώτη σειρά διαλέξεων. Συζητάμε επίσης εφαρμογές από την επεξεργασία φυσικής γλώσσας, και από την ιατρική απεικόνιση.
Ενότητα 2: Η Λογιστική Παλινδρόμηση και η Γεωμετρία του Εσωτερικού Γινομένου
-
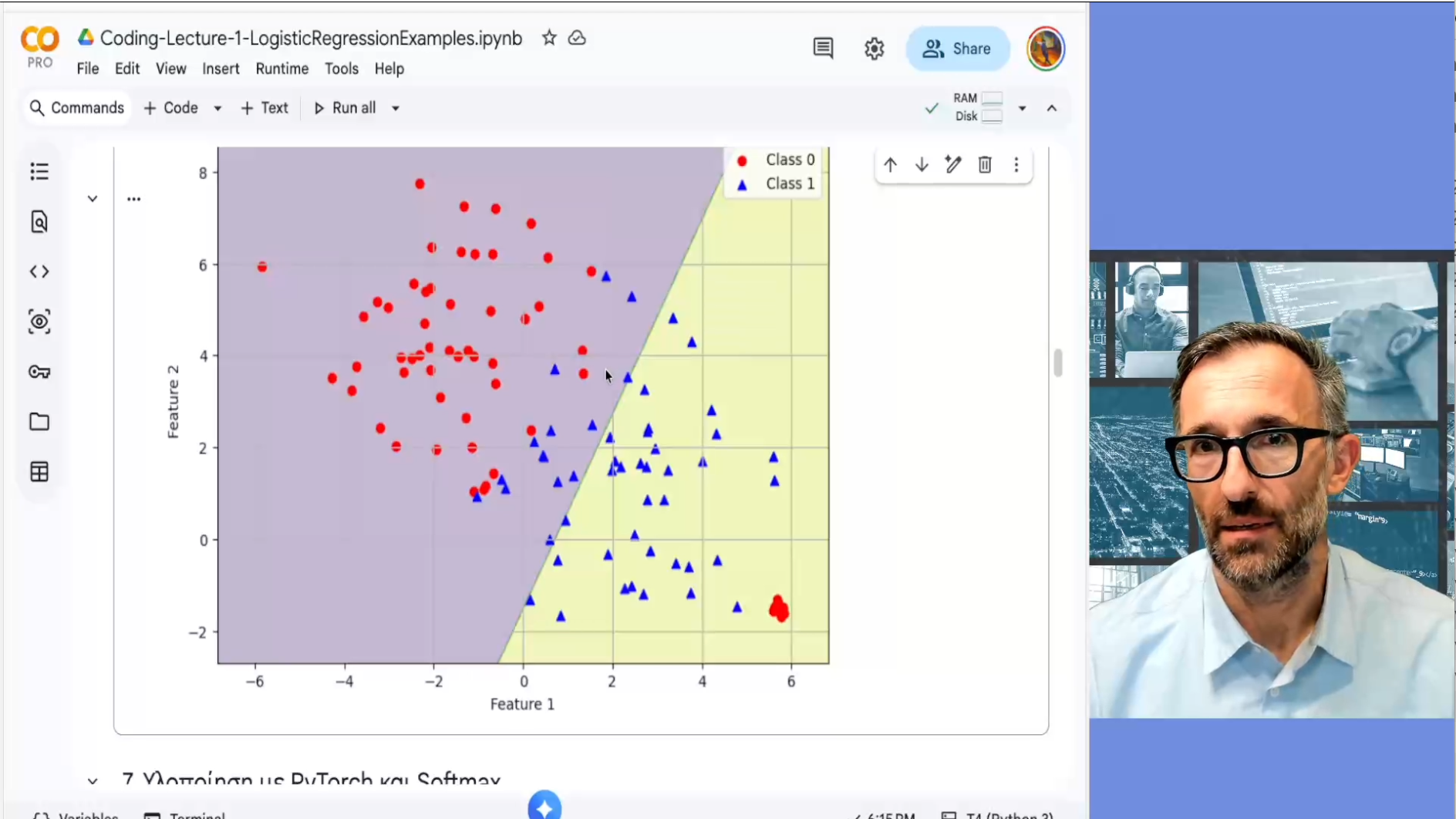
Διάλεξη 3: Λογιστική Παλινδρόμηση και Νευρωνικά Δίκτυα
Σε αυτή τη διάλεξη επιστρέφουμε στη λογιστική παλινδρόμηση, για να καταλάβουμε με μεγαλύτερη λεπτομέρεια πώς λειτουργεί, και τα χαρακτηριστικά των λύσεων που παράγει. Αρχίζουμε με την υλοποίηση χρησιμοποιώντας βιβλιοθήκες της sklearn και στη συνέχεια περνάμε στην υλοποίησή της ως απλού νευρωνικού δικτύου. Βλέπουμε παραδείγματα ταξινόμησης με 2 και 3 κατηγορίες.
-
Διάλεξη 4: Λογιστική Παλινδρόμηση και το Εσωτερικό Γινόμενο
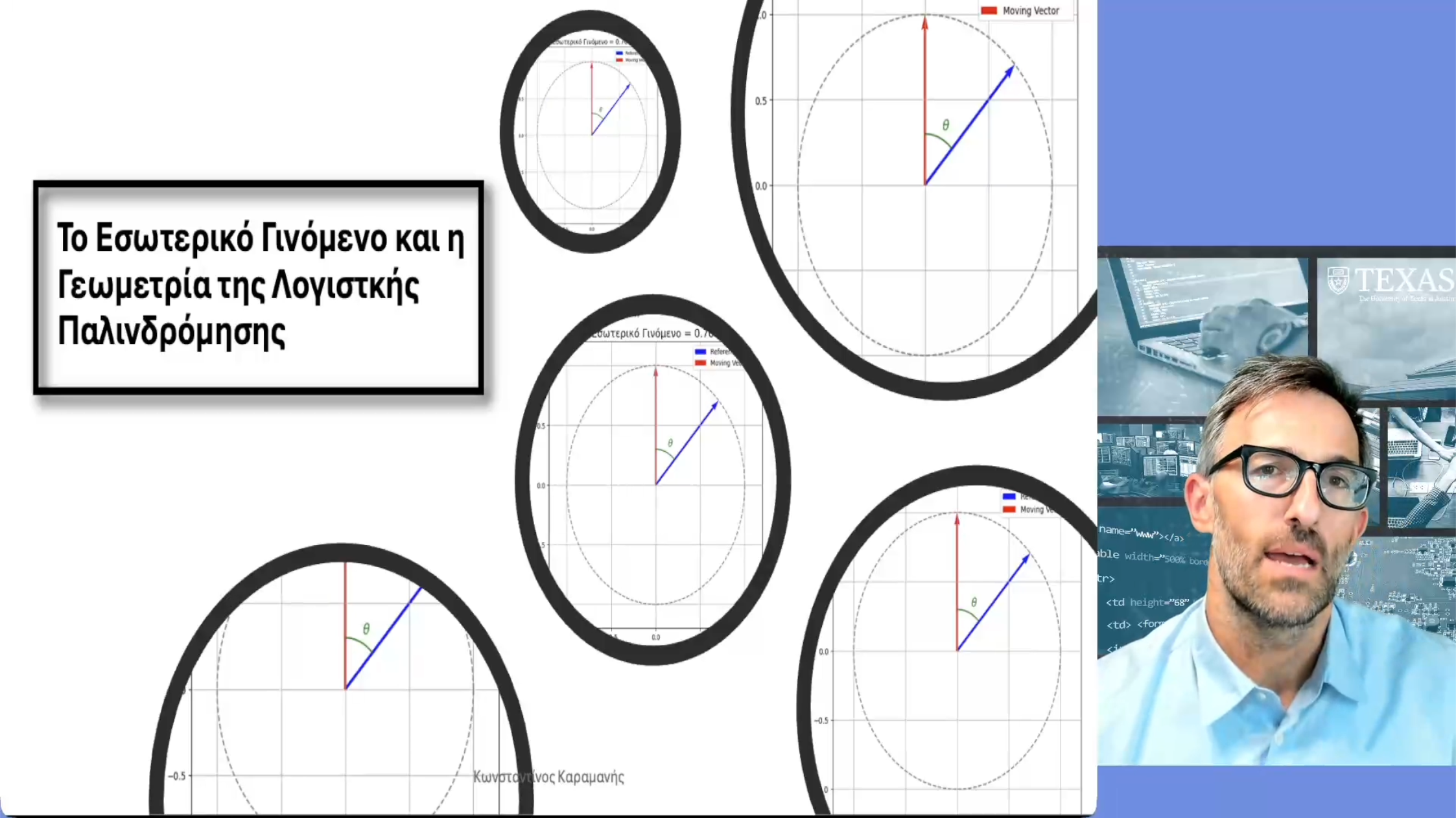
Σε αυτή τη διάλεξη επιστρέφουμε άλλη μια φορά στη λογιστική παλινδρόμηση, και εστιάζουμε στον ρόλο που παίζει το εσωτερικό γινόμενο. Με αυτήν την αφορμή, μελετάμε τις γεωμετρικές ιδιότητες του εσωτερικού γινομένου, στο πλαίσιο της ταξινόμησης. Εδώ αναπτύσσουμε τις βασικές ιδέες που θα μας οδηγήσουν στις σημασιολογικές ενσωματώσεις, στις επόμενες διαλέξεις.
-
Διάλεξη 5: Η Λογιστική Παλινδρόμηση στην sklearn 1/2 (Python / Colab)
Σε αυτή τη διάλεξη χρησιμοποιούμε την Python και τις βιβλιοθήκες της sklearn για να μελετήσουμε τη λογιστική παλινδρόμηση. Συνδέουμε τις ιδέες για τη γεωμετρία του εσωτερικού γινομένου που συζητήσαμε στις προηγούμενες διαλέξεις, με την πράξη, χρησιμοποιώντας παραδείγματα και πειράματα με τεχνητά δεδομένα.
-
Διάλεξη 6: Η Λογιστική Παλινδρόμηση στην PyTorch 2/2 (Python / Colab)
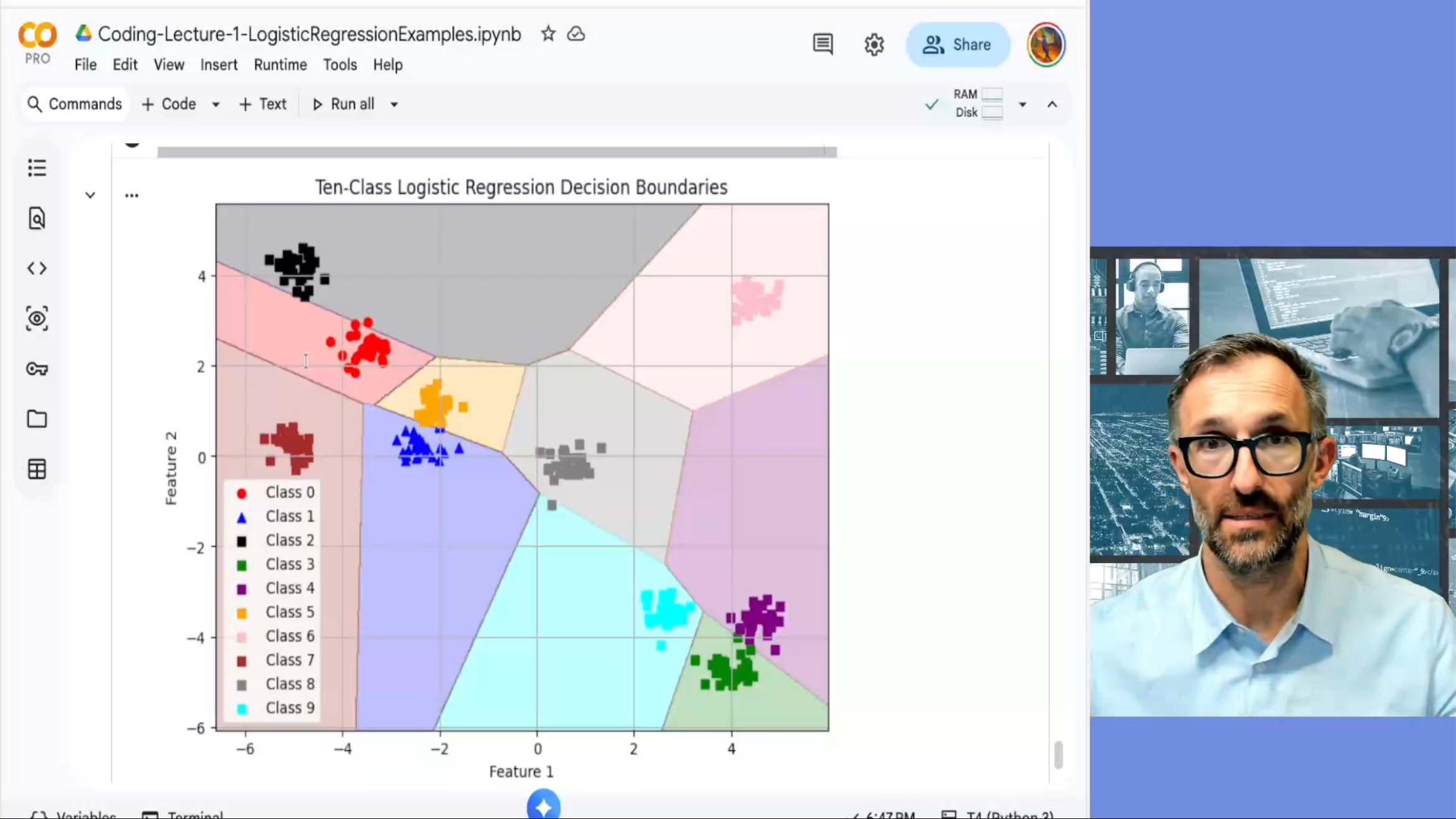
Σε αυτή τη διάλεξη χρησιμοποιούμε την Python και τις βιβλιοθήκες της PyTorch, για να μελετήσουμε τη λογιστική παλινδρόμηση και το εσωτερικό γινόμενο. Επίσης έχουμε την ευκαιρία να παίξουμε με διαφορετικές συναρτήσεις απώλειας, και βλέπουμε πώς αλλάζοντας τη συνάρτηση απώλειας στην εκπαίδευση, αλλάζουμε και τη λύση.
Ενότητα 3: Σημασιολογικές Ενσωματώσεις
-
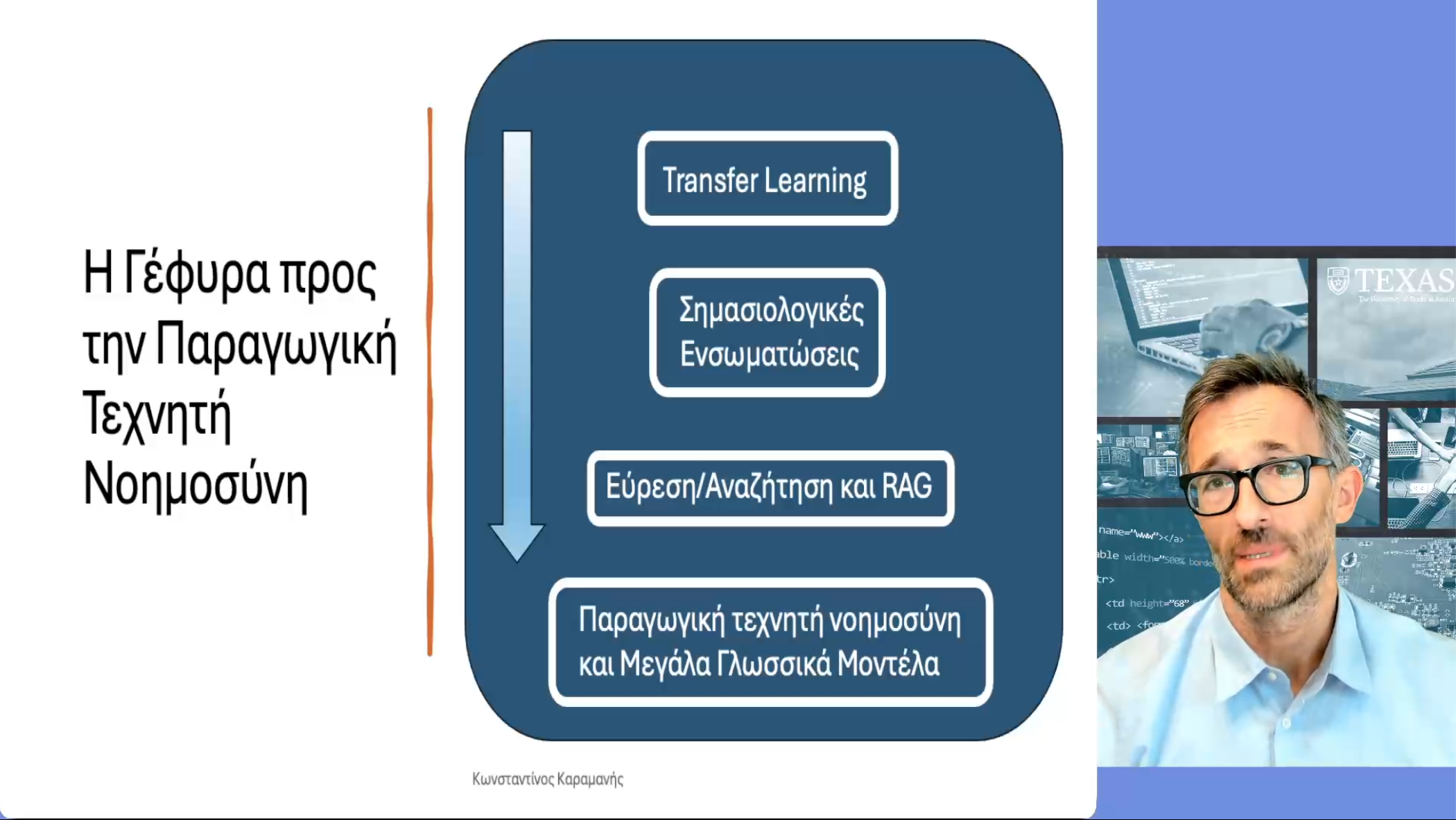
Διάλεξη 7: Σημασιολογικές Ενσωματώσεις: Η Γέφυρα προς την Παραγωγική Τεχνητή Νοημοσύνη
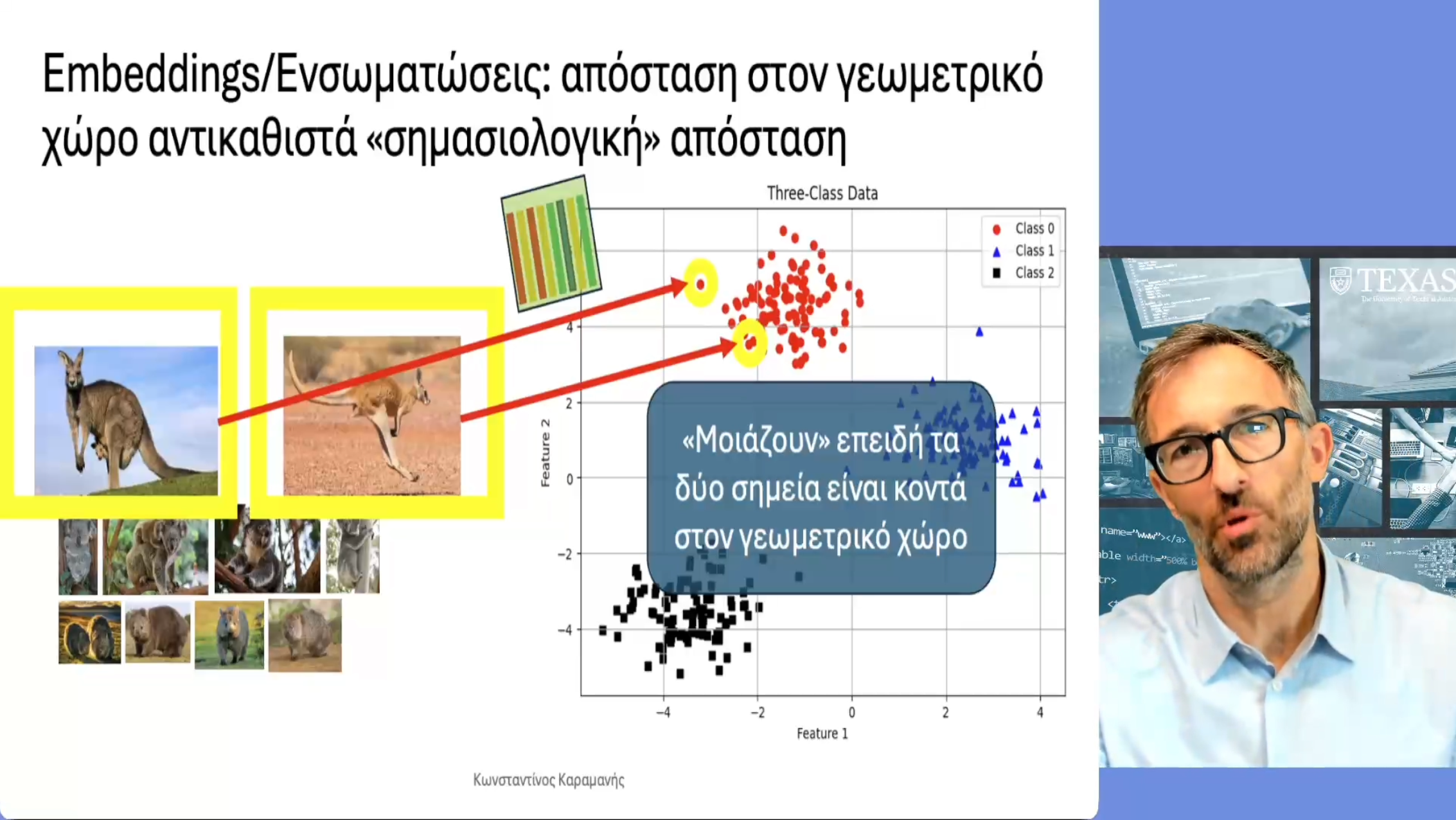
Σε αυτή τη διάλεξη περνάμε από τη λογιστική παλινδρόμηση και το εσωτερικό γινόμενο, στις σημασιολογικές ενσωματώσεις (semantic embeddings). Έτσι περιγράφουμε πώς η ιδέα του Transfer Learning είναι η γέφυρα από την τεχνητή νοημοσύνη, όπως τη συζητήσαμε στην πρώτη σειρά διαλέξεων, και την παραγωγική τεχνητή νοημοσύνη. Τα πρώτα παραδείγματα που δίνουμε είναι από τη μηχανική όραση, μια που με το ResNet18, χτίσαμε (χωρίς καν να το επιδιώξουμε ρητά) ένα νευρωνικό δίκτυο που μας παρέχει καλές σημασιολογικές ενσωματώσεις εικόνων.
-
Διάλεξη 8: Σημασιολογικές Ενσωματώσεις Εικόνων 1/2 (Python / Colab)
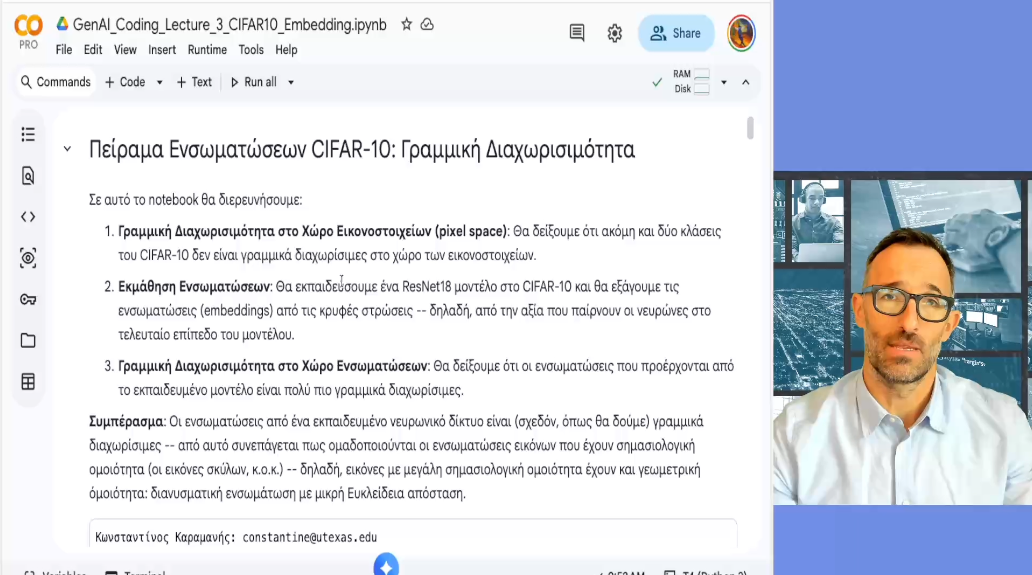
Επιστρέφουμε στην Python για να δούμε τις ιδέες που έχουμε αναπτύξει στην πράξη. Δείχνουμε πώς το ResNet18 που εκπαιδεύσαμε για να λύσουμε το πρόβλημα της ταξινόμησης στις εικόνες της CIFAR-10, μας δίνει επίσης σημασιολογικές ενσωματώσεις εικόνων. Υλοποιούμε διάφορα παραδείγματα ώστε να καταλάβουμε καλύτερα πώς λειτουργούν οι ενσωματώσεις.
-
Διάλεξη 9: Σημασιολογικές Ενσωματώσεις Εικόνων 2/2 (Python / Colab)
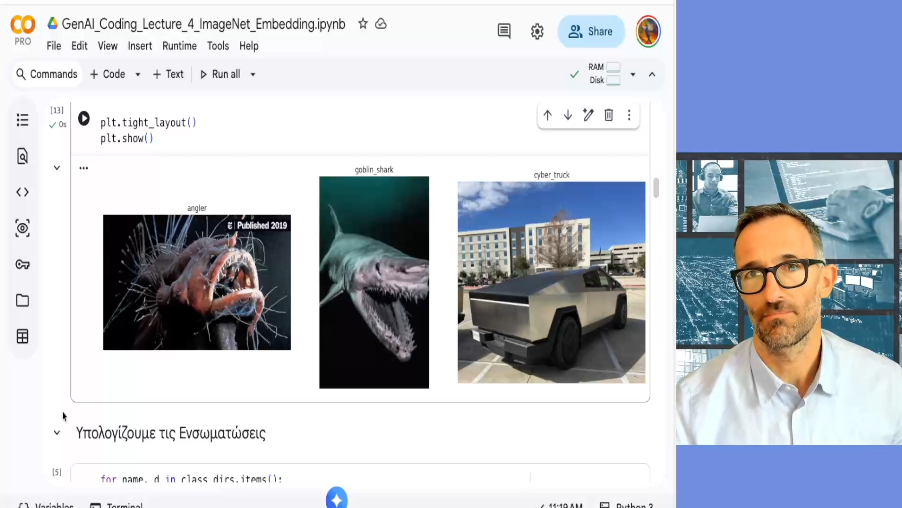
Συνεχίζουμε τη μελέτη μας των ενσωματώσεων μέσω του ResNet18, αυτήν τη φορά χρησιμοποιώντας το προεκπαιδευμένο δίκτυο χωρίς καμία παραπάνω εκπαίδευση στα δικά μας δεδομένα. Κατεβάζουμε εικόνες βατραχόψαρων, καρχαρίων γκόμπλιν, και ένα πολυσυζητημένο ηλεκτρικό όχημα για το οποίο οι αισθητικές γνώμες διίστανται. Βλέπουμε πώς στο χώρο των πίξελ οι εικόνες δεν είναι γραμμικά διαχωρίσιμες, όπως και με προηγούμενα παραδείγματα. Οι σημασιολογικές ενσωματώσεις που προσφέρει το ResNet18 – σημειώνουμε πάλι ότι δεν έχει εκπαιδευτεί πάνω σε αυτά τα δεδομένα, και συγκεκριμένα (a fortiori) το δίκτυο δεν έχει ξαναδεί τουλάχιστον μία από τις τρεις κατηγορίες! – ομαδοποιούν τα δεδομένα. Η σημασιολογική ομοιότητα εκφράζεται (μέσω της ενσωμάτωσης) σε μικρή Ευκλείδεια απόσταση (τα αντίστοιχα σημεία είναι κοντά μεταξύ τους στον χώρο).
-
Διάλεξη 10: Σημασιολογικές Ενσωματώσεις: Word2Vec

Σε αυτή τη διάλεξη περνάμε για πρώτη φορά σε εφαρμογές στη φυσική γλώσσα. Εξηγούμε τη βασική ιδέα του Word2Vec – μια σημασιολογική ενσωμάτωση για περισσότερες από 30.000 λέξεις. Με την Word2Vec η ουσία δεν είναι τόσο οι εφαρμογές (και χρήση του Word2Vec) που προκύπτουν, αλλά η υλοποίηση της ιδέας που αποκαλείται Self-Supervision. Η ιδέα του self-supervision είναι το κλειδί για οποιαδήποτε εφαρμογή απαιτεί την εκπαίδευση μεγάλων γλωσσικών μοντέλων, και θα την ξαναδούμε στις ακόλουθες διαλέξεις.
-
Διάλεξη 11: Σημασιολογικές Ενσωματώσεις: Word2Vec (Python / Colab)
Σε αυτή τη διάλεξη, φορτώνουμε το μοντέλο Word2Vec στην Python και βλέπουμε πώς δουλεύει στην πράξη. Αυτό μας επιτρέπει όχι μόνο να εξετάσουμε τις ενσωματώσεις που μας δίνει το μοντέλο για συγκεκριμένες λέξεις, αλλά επίσης να εξετάσουμε κατά πόσο το μοντέλο πετυχαίνει τον σκοπό του, βλέποντας πώς σχετίζεται η σημασιολογική σχέση δύο λέξεων με την Ευκλείδεια απόσταση των διανυσματικών ενσωματώσεών τους.
Ενότητα 4: Αναζήτηση σε Βάση Γνώσης
-
Διάλεξη 12: Το Πρόβλημα της Αναζήτησης σε Βάση Γνώσης
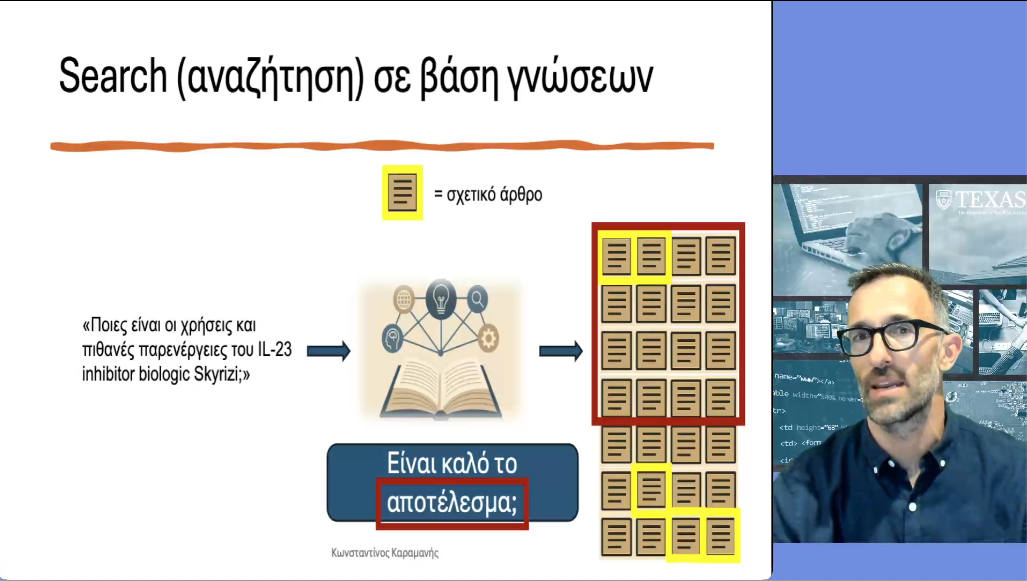
Σε αυτή τη διάλεξη αρχίζουμε τη συζήτησή μας για το πρόβλημα της αναζήτησης σε μια βάση γνώσης. Θα μας απασχολήσει για αρκετές διαλέξεις, και θα λειτουργήσει ως το σημείο εκκίνησης για τη μελέτη μας για τα μεγάλα γλωσσικά μοντέλα. Το ζήτημα της αναζήτησης αποτελεί αυτό καθαυτό ένα σημαντικό και σύνθετο πρόβλημα, με πλήθος και ποικιλία εφαρμογών. Περιγράφουμε το βασικό πρόβλημα, και εισάγουμε τα βασικά μέτρα αξιολόγησης: NDCG και Recall.
-
Διάλεξη 13: Κλασική Αναζήτηση: Bag-of-Words και TF-IDF

Αυτή η διάλεξη περιγράφει τις κλασικές μεθόδους αναζήτησης, συγκεκριμένα, το TF-IDF. Προς θεμελίωση της τεχνικής του TF-IDF, εξετάζουμε πρώτα το Bag-of-Words. Χρησιμοποιούμε ένα μικρό παράδειγμα αναζήτησης, στο οποίο επιστρέφουμε στην επόμενη διάλεξη, χρησιμοποιώντας τα εργαλεία της Python.
-
Διάλεξη 14: Bag-of-Words και TF-IDF σε Python 1/2 (Python / Colab)
Υλοποιούμε τις δύο μεθόδους, Bag-of-Words και TF-IDF σε Python, και σε μικρά και μεσαίου μεγέθους προβλήματα, βλέποντας διαισθητικά πώς λειτουργούν, αλλά και αξιολογώντας την απόδοσή τους χρησιμοποιώντας το NDCG και το Recall. Είναι επίσης αφορμή να μάθουμε για χρήσιμες βιβλιοθήκες της Python για την επεξεργασία κειμένου, όπως την NLTK.
-
Διάλεξη 15: Bag-of-Words και TF-IDF σε Python 2/2 (Python / Colab)
Συνεχίζουμε τη συζήτηση για την υλοποίηση του TF-IDF στην Python, εστιάζοντας σε θέματα αποδοτικότητας και συγκεκριμένα, στην κατασκευή του inverted index (αντεστραμμένο ευρετήριο). Το inverted index είναι βασικό και απαραίτητο στοιχείο για τη λειτουργία του TF-IDF (και ΒΜ25) για προβλήματα ανάκτησης από βάση γνώσης.
-
Διάλεξη 16: Αναζήτηση με Σημασιολογικές Ενσωματώσεις Κειμένου και RAG
Σε αυτή τη διάλεξη περνάμε στις σύγχρονες τεχνικές αναζήτησης, που χρησιμοποιούν σημασιολογικές ενσωματώσεις κειμένου. Εξηγούμε τη βασική μεθοδολογία, χωρίς να μπούμε ακόμα στις λεπτομέρειες για το πώς χτίζονται οι ενσωματώσεις. Μιλάμε όμως λεπτομερώς για το πώς χτίζουμε ένα σύστημα RAG (Retrieval-Augmented Generation) με σημασιολογικές ενσωματώσεις. Τα RAG προσφέρουν τη βασική ιδέα που επιτρέπει σε ένα ήδη εκπαιδευμένο γλωσσικό μοντέλο, είτε ανοιχτό, όπως το Llama ή το Qwen, είτε κλειστό, όπως ένα μοντέλο GPT ή το Claude, να αξιοποιεί εξωτερική γνώση.
-
Διάλεξη 17: Αναζήτηση με Σημασιολογικές Ενσωματώσεις σε Python (Python / Colab)
Υλοποιούμε τη σημασιολογική αναζήτηση χρησιμοποιώντας βιβλιοθήκες της Huggingface, και συγκρίνουμε τα αποτελέσματά μας με το προηγούμενο notebook μας με TF-IDF/BM25. Η Huggingface μας προσφέρει πλούσια συλλογή από μοντέλα (εκπαιδευμένα νευρωνικά δίκτυα) για μηχανική όραση και επεξεργασία φυσικής γλώσσας, αλλά και πολλά και πολύ χρήσιμα σύνολα δεδομένων που μας επιτρέπουν να αξιολογίσουμε δικά μας μοντέλα με βάση την ακρίβειά τους σε αυτά τα δεδομένα. Επίσης προσφέρει χρήσιμες βιβλιοθήκες και εργαλεία για τη χρήση και εκπαίδευση νευρωνικών δικτύων. Με λίγα λόγια, είναι ένας πολύ χρήσιμος πόρος για τη χρήση και μελέτη νευρωνικών δικτύων.
Ενότητα 5: Μεγάλα Γλωσσικά Μοντέλα
-
Διάλεξη 18: Συμφραστικές ενσωματώσεις (contextual embeddings), και το Masked Language Modeling (MLM)
Πώς εκπαιδεύεται ένα μεγάλο γλωσσικό μοντέλο όπως το BERT, για να παράγει καλές σημασιολογικές ενσωματώσεις κειμένου (semantic embeddings), καθώς και συμφραστικές (ή συμφραζόμενες) ενσωματώσεις λέξεων (contextual semantic embeddings); Σε αυτή τη διάλεξη εξηγούμε πώς χρησιμοποιείται η ιδέα του self-supervision που πρωτοείδαμε στο πλαίσιο του Word2Vec, για τη δημιουργία ενός προβλήματος επιτηρούμενης μάθησης, για την εκπαίδευση ενός μεγάλου γλωσσικού μοντέλου που παράγει ενσωματώσεις. Εξηγούμε σε λεπτομέρεια το λεγόμενο Masked Language Modeling (MLM), και πώς εκπαιδεύεται το BERT.
-
Διάλεξη 19: Η Χρήση του BERT για προβλήματα ταξινόμησης στη φυσική γλώσσα
Αφού εκπαιδευτεί το BERT με Masked Language Modeling (MLM), όπως συζητήσαμε στην προηγούμενη διάλεξη, μπορεί να χρησιμοποιηθεί για να λύσει μια μεγάλη ποικιλία προβλημάτων στη φυσική γλώσσα. Σε αυτή τη διάλεξη εξηγούμε πώς μπορούμε να προσαρμόσουμε (με εκπαίδευση και transfer learning) το BERT για να λύσουμε προβλήματα ταξινόμησης στη φυσική γλώσσα. Συγκεκριμένα, εξετάζουμε κάποια προβλήματα από το λεγόμενο GLUE – μια συλλογή από προβλήματα ταξινόμησης στη φυσική γλώσσα.
-
Διάλεξη 20: Χρησιμοποιώντας το μοντέλο BERT για προβλήματα ταξινόμησης, στην Python (Python / Colab)
Στην προηγούμενη διάλεξη εξηγήσαμε πώς εφαρμόζεται η θεωρία. Εδώ γυρνάμε στην πράξη, και υλοποιούμε στην Python τη λύση στο πρόβλημα ταξινόμησης που λέγεται CoLA – ένα πρόβλημα που απαιτεί να ταξινομήσουμε αν μια φράση (στα αγγλικά) είναι σωστή από γλωσσική (και όχι μόνο γραμματική) άποψη. Χρησιμοποιούμε μοντέλα και βιβλιοθήκες της Huggingface.
-
Διάλεξη 21: Προσαρμογή Μοντέλου (fine tuning) για τη σημασιολογική αναζήτηση: InfoNCE
Πώς εκπαιδεύουμε ένα μοντέλο όπως το BERT πάνω στα δικά μας δεδομένα, για να βελτιώσουμε την επίδοσή του σε προβλήματα σημασιολογικής αναζήτησης; Σε αυτή τη διάλεξη περιγράφουμε το λεγόμενο Contrastive Learning (που θα το ξανασυναντήσουμε όταν συζητήσουμε το CLIP), και το InfoNCE (Information Noise-Contrastive Estimation). Συζητάμε επίσης και το σημαντικό πρόβλημα της κατασκευής σετ δεδομένων για αυτόν τον σκοπό. Επίσης αναφέρουμε τα λεγόμενα bi-encoders και cross-encoders, καθώς και τον τρόπο με τον οποίο εκπαιδεύονται και χρησιμοποιούνται.
-
Διάλεξη 22: Το Transformer και το Self-Attention
Σε αυτή τη διάλεξη ανοίγουμε το μαύρο κουτί, και εξετάζουμε λεπτομερώς την αρχιτεκτονική του λεγόμενου Transformer. Το Transformer χρησιμοποιήθηκε αρχικά στην επεξεργασία φυσικής γλώσσας, αλλά πιο πρόσφατα χρησιμοποιείται επιτυχώς και για προβλήματα μηχανικής όρασης, τόσο σε ταξινομητές όσο και σε μοντέλα diffusion.
-
Διάλεξη 23: Μεγάλα Γλωσσικά Μοντέλα και η παραγωγή της γλώσσας.
Σε αυτή τη διάλεξη εξηγούμε την αρχιτεκτονική των μεγάλων γλωσσικών μοντέλων, και πώς παράγουν φυσική γλώσσα τα λεγόμενα Auto-Regressive μοντέλα όπως το GPT, τα μοντέλα Qwen, και άλλα.
-
Διάλεξη 24: Προσαρμογή ενός Μεγάλου Γλωσσικού Μοντέλου στην Python (Python / Colab)
Περνάμε από τις διαφάνειες στην Python. Χρησιμοποιούμε βιβλιοθήκες της Huggingface για να φορτώσουμε ένα μεγάλο γλωσσικό μοντέλο που παράγει φυσική γλώσσα. Ύστερα, το προσαρμόζουμε (fine tuning) πάνω σε ένα μικρό σώμα κειμένων του Shakespeare. Βλέπουμε πώς αυτή η επιπρόσθετη εκπαίδευση αλλάζει τη συμπεριφορά του μοντέλου.